“Will humanity solve Intelligence?”, is a lingering question of this century. Also the much less likely, “Is singularity a possible threat?” sits in a corner. What people miss out is that creating a self-aware sentient being is no less task than that of a human playing God. Now, why exactly do we bother ourselves with creating Artificial Intelligence? It could be as abstract as this, “The reason why anyone who would do this if they could, would be because that they could” quoting Rick, from Rick and Morty. As a robotics and AI enthusiast myself, the possibility of creating a system capable of adapting to changes, thinking like us and breaking the barrier of nature’s evolution thrills me.
When encountered with AI, many get paranoid, conceiving only the doomsday scenarios such as those in Terminator, I Robot or Black Mirror. But in reality, AI has just taken baby steps in a strenuous endeavour to reach human intelligence. Present scenario, AI has the intelligence of at most a worm, in terms of collective rationality. Anyone working in the field of Reinforcement Learning1 (RL) and Deep Learning (DL) will be able to sketch out the difficulties and nitty-gritties involved in making a true AI system. Any system capable of taking decisions in a particular problem has to be trained with relevant data for days together, a bottleneck of traditional machine learning (RL comes as a relief with its sparse feedback and reward structure). One important factor to notice here is that the training and corresponding learning usually deals with well-defined identifiable problems such as predicting the next sentence in a conversation or achieving a better score in an Atari game like Pac-Man.
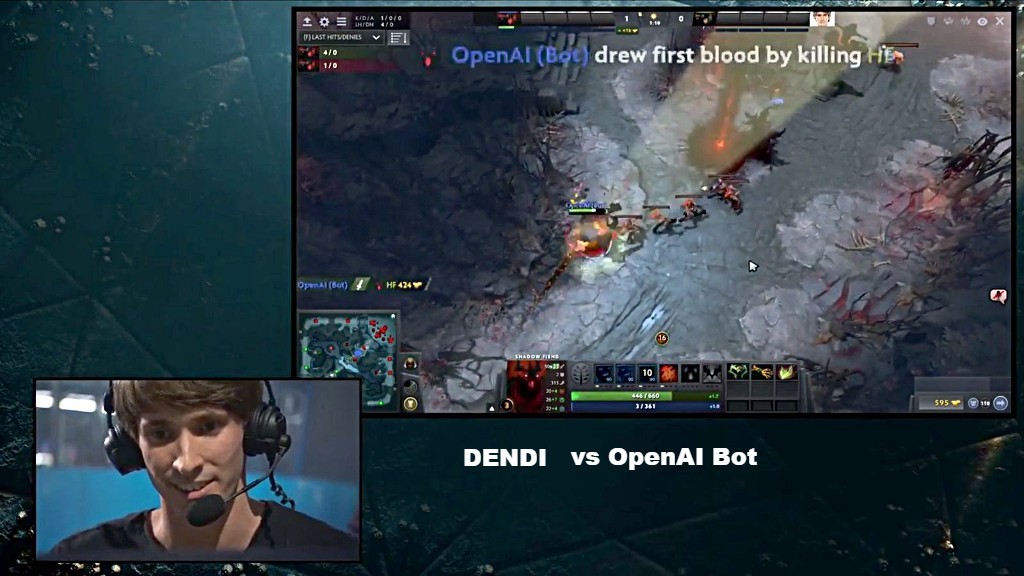 Image courtesy: The Verge; In photo: Screenshot of DOTA2 during gameplay between Dendi and the bot by OpenAI
Image courtesy: The Verge; In photo: Screenshot of DOTA2 during gameplay between Dendi and the bot by OpenAI
It is true that computers have learnt to outperform humans in well-defined specific tasks, recent one being, the bot built by OpenAI (Elon Musk backed startup) defeating Dendi, considered the world’s best human player in DOTA2, a strategy e-sport game. The creators say that the bot learnt to bait and exploit other players who bait in the game, which is kind of incredible. This taste of drastic progress that we are witnessing right now is unlike the slow progress throughout 19th and 20th century which saw several AI winters.
When Google DeepMind’s AlphaGO (cover picture) beat the best human player in the most difficult ancient Chinese Board game GO, AI speculators were dumbfounded because this development was not expected at least for a couple of decades. Simply because the number of outcomes from a GO board position is larger than the number of atoms in the universe and that brute forcing or hard coding is not possible. This year again we had Libratus from CMU which beat best human players in Texas Hold ‘em which is a tougher version of poker. In terms of Game Theory, it is an imperfect information game which means that information about the opponent’s strategy is hidden and is thus harder to model. The AI scholar groups were surprised at the bot’s capability to bluff, which earlier was thought that something only humans can do. And it’s not just games in which AI is creating impact. It is revolutionising the way we commute, through self-driving cars; speech synthesizers such as Amazon Alexa and Google Assistant are now able to understand the context in multiple line commands and have a sensible argument; Facebook has trained AI bots with ability to negotiate deals, and all these have just happened in a span of a couple of years.
True Intelligence:
Having said all this, I consider that true intelligence has been reached only when continuous learning is accomplished. For us humans, this kind of learning is what we practice from our birth. We have the most tangled circuitry in our own heads (yes, much more than your tangled earphones) to relate seemingly discrete things from distinct thoughts. Given any scenario and the information about it, we are capable of selective processing and coming up with a conclusive decision which in other terms, we call rationality. To be precise, we are able to relate the learning in one sector and apply it to a different sector and if required, retain the learning. Understanding puns, is a best example to depict this seemingly simple, yet intelligent behaviour of humans. Excuse me for throwing this cruel dad joke: Dad said, “Feeling cold sweetie? Go sit in a corner”. Daughter goes, “How does that help?” for which dad replies with a smug, “Because they’re 90 degrees.” Before you put your palm on face, pat on your back because you were, as a human, able to relate knowledge from two different domains namely, geometry and temperature metrics.
What we take for granted, is an extremely exigent task for a robot, as the algorithms that are executed for specific tasks are just written as stand-alone codes. One naive way to solve at this problem is to make the system re-apply the knowledge gained from learning various specific tasks by switching controls between the executables. This could mean an overseen binding of all codes like a fully functional OS, except that the system should not expect a command from a human. The closest thing we have to this is in RL, where people are exploring the possibilities of policy switching and it is still an open-ended problem.
The reason why people don’t focus on solving the whole problem is because it’s too hard. Thus, the AI that we notice today has narrow competencies. We human beings have brains which are fairly complex and no system at present on earth can perform the kind of job it does. Now why do all AI science fiction movies have rogue robots? Well, it’s just way cooler to contemplate killer robots than robots that bring you tea; killer robots which “went out of humans’ hands”; killer robots which human protagonists win over to establish narcissistic superiority. Allow me to quote Andrew Ng, one of the pioneers in Deep Learning, “Worrying about some kind of intelligent evil AI taking over the world, is about as rational as worrying about overpopulation on mars right now. We haven’t even landed on the planet yet”.
More revelations to come..
-
Reinforcement Learning: The branch of Machine Learning which deals with training agents to act ‘right’ in an environment with rewards and punishments as feedback. The goal of the agent would be to maximize the cumulative rewards in it’s episodes. RL has origins in behavioral psychology and thus learns to do tasks similar to how a human would learn. ↩
{kind=link}