VLAs - Pixels to Actions
On the cover: Pixels to actions
In our last post, we taught a Transformer to see and speak. We bolted a vision encoder onto an LLM, projected pixel-patches into the language space, and tricked the text model into hallucinating a vision system. The result was a model that can look at a picture of your fridge and write you a thousand words on apples.
Lovely. Now ask it to actually pick up the apple.
The model will keep describing the apple with poetic precision, but it will not move a millimeter. We have built the world’s most articulate paperweight, and the natural next question for roboticists around 2023 was: we have a model that can see and talk, what happens if we give it hands?
Welcome to the era of Vision-Language-Action models (VLAs). This is the story of how AI stopped being a tour guide and started being a worker.
The problem
VLMs can do almost everything a robot needs to do, except the part where the robot actually does something. They understand the scene, they know what “pick up the apple” means, and they can plan a multi-step recipe in natural language. They simply cannot output motor commands, because their vocabulary is just “pick up the apple” that doesn’t translate to any tangible outcome.
You might think the fix is to slap a regression head on the VLM and predict joint angles directly. This is, technically, what people tried first, and it mostly didn’t work. The moment you fine-tune the model on a few thousand robot trajectories, you erase the web knowledge that made the VLM useful in the first place. The model that could quote Wikipedia about apples now only knows how to pick up apples in one specific lighting condition on one specific kitchen counter.
So the question becomes: how do you give the model hands without making it forget everything else?
The anatomy of a VLA
Before we dive into specific models, here’s the generic recipe every VLA follows. Three components: a vision encoder that turns pixels into tokens (your old friend the ViT), a vision adapter that converts pixel tokens to language space, an LLM backbone that fuses image tokens with language tokens and reasons about what to do, and an action head (either the same LLM head or a separate decoder) that turns the LLM’s outputs into motor commands or trajectory waypoints.
The variants we’ll see next differ almost entirely in how that last piece works: discrete token decoding (RT-2, OpenVLA), continuous regression, or denoising-based generation (π₀). Everything else is mostly scale and data.
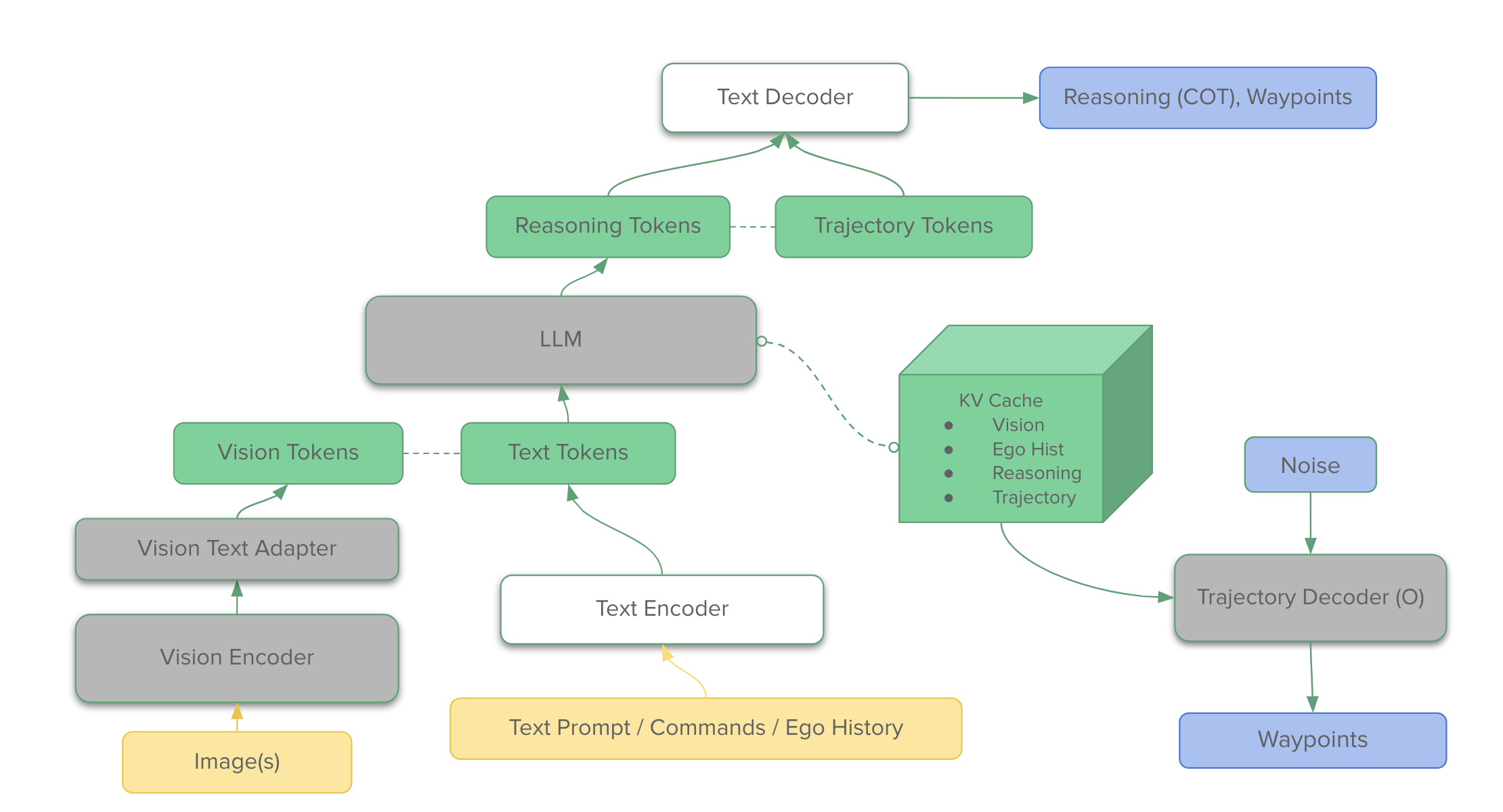 Figure 1: The generic architecture of a Vision-Language-Action model (shown for autonomous driving, but applicable for robotics as well). Pixels and instruction are tokenized and fused by a VLM backbone; the action head decodes those into motor commands or trajectory waypoints.
Figure 1: The generic architecture of a Vision-Language-Action model (shown for autonomous driving, but applicable for robotics as well). Pixels and instruction are tokenized and fused by a VLM backbone; the action head decodes those into motor commands or trajectory waypoints.
With that template in hand, let’s see how the major VLAs of 2023–2025 fill in each box.
The translator (RT-2)
The first serious answer came from Google DeepMind in 2023 with RT-2: Vision-Language-Action Models Transfer Web Knowledge to Robotic Control. The insight is one of those obvious-in-retrospect tricks: if the LLM only speaks tokens, just write the action as text.
Step 1: the butcher shop, again
A 7-DoF robot arm has 7 continuous numbers per timestep (3 position deltas, 3 rotation deltas, 1 gripper) plus a termination flag. Continuous numbers and Transformers don’t mix, so RT-2 takes a cleaver to each dimension and slices the continuous range into 256 discrete bins. Formally, for action $a_i$ along dimension $i$ with bounds $[a_{\min}, a_{\max}]$:
\[\text{bin}(a_i) = \left\lfloor \frac{a_i - a_{\min}}{a_{\max} - a_{\min}} \cdot 255 \right\rfloor\]Each action is now eight integers between 0 and 255, and a whole robot trajectory becomes a string that looks suspiciously like a phone number:
Instruction: pick up the apple. Action: 1 128 91 241 5 101 127 255
A continuous control problem is now a translation task.
Step 2: the dictionary smuggle
Now you need the LLM to actually have tokens for these integers. PaLI-X (one of RT-2’s backbones) already has unique tokens for every integer 0–999, so you get this for free. PaLM-E (the other) doesn’t, so the authors do something delightfully hacky: they grab the 256 least-frequent tokens in PaLM-E’s vocabulary and quietly overwrite them to mean “action bin 0”, “action bin 1”, and so on. The LLM never notices its rarest tokens have been repurposed as motor commands.
Step 3: don’t forget Wikipedia (co-fine-tuning)
Here’s where it gets interesting. If you fine-tune only on robot data, the VLM forgets everything else, and apples become “things you pick up” instead of “fruit, red, ~95 calories, banned in some keto diets”. So RT-2 trains on mixed batches (roughly half web data, half robot data) throughout fine-tuning. The web tasks keep the semantic knowledge alive while the robot tasks teach the action tokens.
The ablation is striking: with co-fine-tuning, generalization to unseen tasks jumps from 52% to 63%. Train from scratch on the smaller 5B model without web pretraining and it collapses to 9%. Without the web scale, nothing transfers.
 Figure 2: RT-2 architecture. Source: RT-2
Figure 2: RT-2 architecture. Source: RT-2
The emergent behaviors are where RT-2 stops looking like a control policy and starts looking like a strange new kind of intelligence. “Move the can on top of the heart” works, even though there are no hearts in the robot data. “Move the banana to the sum of two plus one” works. Multilingual instructions work. None of this is in the demonstrations; it leaks in from the web.
The catch is latency. The 55B model runs at 1–3 Hz on a multi-TPU cloud service, which means your robot is essentially waiting for the cloud to text it back every second.
The open cousin (OpenVLA)
RT-2 was closed weights, closed data, and closed everything. So in 2024, a Stanford/Berkeley/Google team released OpenVLA, a 7B-parameter VLA that at one-eighth the size beats RT-2-X by 16.5 percentage points across 29 tasks.
The architecture is RT-2’s recipe with a few sharpenings. The big one is vision: OpenVLA runs every image through two encoders in parallel. SigLIP (~400M, contrastive) knows what things are, and DINOv2 (~300M, self-supervised) knows where things are. The patch tokens are concatenated channel-wise, so SigLIP can recognize that the object is a mug while DINOv2 keeps track of where the handle is. Dropping either one costs about 10 points on language-grounded manipulation.
The rest is familiar: same 256-bin discretization per action dimension, same token-overwriting trick on Llama-2 7B’s vocabulary. One tweak that matters is that bin edges are placed at the 1st–99th percentile per dimension instead of min/max, so outliers don’t compress the resolution you actually use. Training ran on the Open X-Embodiment dataset, ~970K trajectories from 22 different robots assembled by 21+ labs. The model never sees a single robot; it sees the whole zoo. Training takes 64 A100s for 14 days.
 Figure 3: OpenVLA architecture. Source: OpenVLA
Figure 3: OpenVLA architecture. Source: OpenVLA
The killer feature is LoRA fine-tuning for new robots. Got a new arm? You don’t need to retrain 7B parameters. A rank-32 LoRA adapter (97.6M params, 1.4% of the model) trains on a single A100 for 10–15 hours and matches full fine-tuning. Inference at 4-bit quantization runs ~6 Hz on a single RTX 4090, so a generalist robot policy now fits on a hobbyist’s GPU.
OpenVLA’s honest weakness is that it doesn’t co-train with web data the way RT-2 did. It manipulates better and generalizes semantically worse. Pick your poison.
The flow heretics (π₀)
Discretizing actions into 256 bins works fine for tabletop pick-and-place. It does not work for inserting a USB, and it really doesn’t work for folding a t-shirt. 1/256 ≈ 0.4% resolution per dimension sounds like a lot until you realize you need sub-millimeter precision to thread a cable.
There’s a second problem too. Autoregressively decoding 50 future actions × 18 dimensions sequentially is 900 forward passes, which you cannot run at 50 Hz no matter how clever your KV cache is.
In late 2024, Physical Intelligence published π₀: A Vision-Language-Action Flow Model for General Robot Control, which addresses both problems at once.
The architecture: two experts, one brain
π₀ uses PaliGemma 3B as the VLM backbone and adds a separate 300M-parameter “action expert” Transformer initialized from scratch. The trick is that it’s a single Transformer where every layer has two parallel sets of weights, and each token is routed to one set based on what kind of token it is. Image and text tokens flow through the PaliGemma weights, action tokens flow through the action expert. Attention is shared across the whole sequence so actions can look at images at every layer, but the projection matrices are separate.
This buys two things. The VLM prefix is computed once and KV-cached, while the small action expert can be re-run many times during denoising. And the robot signal (which is low-diversity) never overwrites the VLM’s web knowledge (which is high-diversity).
Flow matching, in one paragraph
Instead of predicting action tokens autoregressively, π₀ generates a whole chunk of 50 continuous actions at once via flow matching. The idea is dead simple. Pick a target action chunk $A$, sample noise $\epsilon \sim N(0, I)$, and pick a flow-time $\tau \in [0, 1]$. Linearly interpolate:
\[A^\tau = \tau A + (1 - \tau)\epsilon\]The straight-line vector pointing from noise to data is, trivially:
\[u = A - \epsilon\]Train a network $v_\theta$ to predict that vector:
\[Loss = \mathbb{E}_{A, \epsilon, \tau}\left[\|v_\theta(A^\tau, o, \tau) - (A - \epsilon)\|^2\right]\]At inference, start from pure noise and integrate forward with Euler steps. Ten steps is enough.
If you’ve seen diffusion, this is its straight-line cousin. Compared to diffusion’s curvy paths, flow matching’s paths are linear, so you need fewer steps. Compared to autoregressive token decoding, you get all 50 × 18 = 900 continuous values in 10 parallel forward passes of a small action expert. That’s how π₀ gets to 50 Hz.
 Figure 4: π₀ architecture. Source: π₀ paper
Figure 4: π₀ architecture. Source: π₀ paper
Action chunking
The “predict 50 actions at once” part isn’t original to π₀; it comes from Action Chunking Transformers (ACT) in 2023. The insight is that predicting one action at a time accumulates error and ignores the multi-second intent in human teleop data. Predict a chunk, commit to a motor program, execute it. Success rates on hard tasks go from 1% (k=1) to 44% (k=100). Chunking is half the reason modern VLAs work.
π₀ demonstrates this on tasks earlier VLAs simply could not do: folding laundry, bussing tables, packing eggs. OpenVLA scores roughly zero on these because quantization and single-step prediction both collapse on fine motor tasks. The follow-ups π₀.₅ and π*₀.₆ extend the recipe to unseen homes and add online RL post-training, with the latest model running 5 denoising steps in 63 ms on an H100.
VLAs behind the wheel
Driving used to be separate modules for perception, prediction and planning that handled scene understanding, localization, and control respectively. Modern VLAs are changing that by treating driving as a unified, end-to-end control problem.
Robot manipulation VLAs predict end-effector deltas. Driving VLAs on the other hand predict trajectories (typically 3–8 seconds of future waypoints in BEV space assuming the ego car at the origin) that a downstream low-level controller turns into steering and throttle commands. Different action space, same recipe. Here’s three models to look at the history in this field:
EMMA (Waymo, 2024): EMMA uses Gemini as the backbone and serializes future waypoints as plain text: $(x_1, y_1) (x_2, y_2) …$. No special tokens, no specialized heads, the model is literally trained to write floating-point numbers. Detection boxes, road graphs, and trajectories all come out as text from one model, with optional chain-of-thought before the trajectory (“there is a cyclist on the right, I will yield”). It’s camera-only and closed-weights, but reduces nuScenes L2 by 17% over the BEV-Planner baseline.
DriveVLM-Dual (Tsinghua + Li Auto, 2024): DriveVLM is the canonical “slow brain, fast body” architecture. A Qwen-VL backbone does three-stage chain-of-thought planning (scene description, then critical-object analysis, then 17 meta-actions like slow_down, turn_left), and a fast conventional planner consumes the coarse trajectory at higher frequency. The VLM thinks; the classical stack executes. This is actually shipping in production Li Auto vehicles.
Alpamayo-R1 (NVIDIA, 2025): Alpamayo-R1 is the closest production-driving VLA to π₀’s design philosophy. A 10B model: Cosmos-Reason 8B VLM backbone plus a 2.3B flow-matching action expert. Inputs are 4 cameras at 10 Hz, and the output is 64 waypoints over 6.4 seconds, parameterized as acceleration + curvature under a unicycle model rather than raw (x, y). Latency is 99 ms on an H100. The interesting part is the training data: 80,000 hours of fleet driving plus 700k Chain-of-Causation traces, which are structured causal chains tying scene evidence to driving decisions. Weights are released on HuggingFace under a non-commercial license.
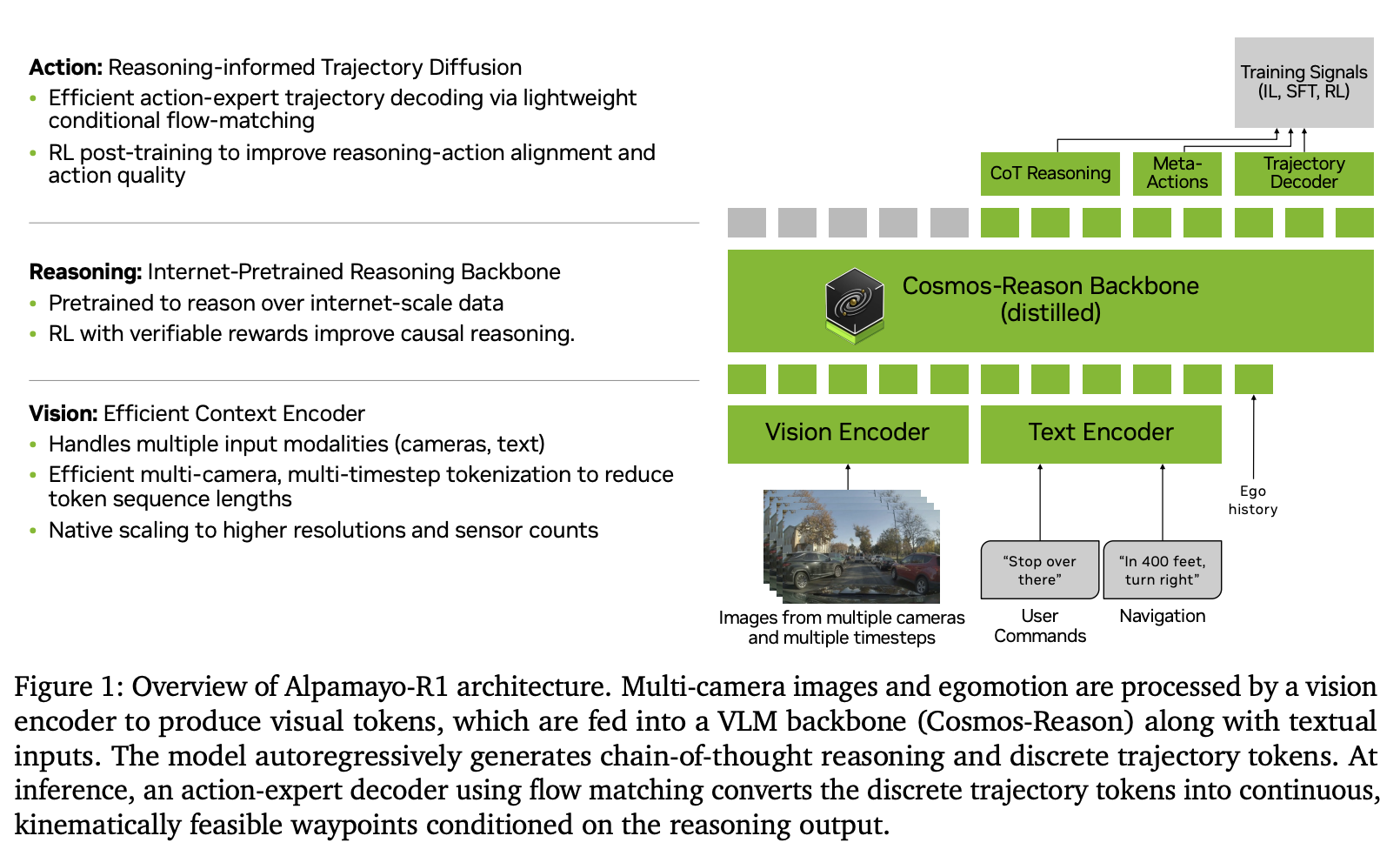 Figure 5: Alpamayo-R1 architecture. Source: Alpamayo-R1
Figure 5: Alpamayo-R1 architecture. Source: Alpamayo-R1
The shared trend across driving VLAs is that serializing waypoints as text (EMMA-style) is fine for benchmarks but hits a precision and latency ceiling, so the field is shifting toward continuous action heads. Open-source contributions like OpenDriveVLA, ORION, CoReVLA, WiseAD, and SafeAuto each take a different angle on the same problem: how to combine VLM-grade reasoning with control-grade latency. Closed-loop (as in act in the environment and observe the results) benchmarks like Bench2Drive and NAVSIM have largely replaced nuScenes open-loop (just the regression error over trajectories) L2, because the older metrics turned out to be gameable with ego-state shortcuts.
Why this matters
We can see that the unifying thesis from the ViT post is finally paying off. Everything is a token. Image patches are tokens. Words are tokens. Robot actions are tokens. The same Transformer that summarizes your email can fold your shirt, given the right fine-tuning data.
But there’s a deeper point. VLAs scale because they sit on top of a VLM that already knows what a “apple” is, what “left of the toaster” means, and what “carefully” implies about gripper force. The robot data doesn’t have to teach the model the world. It only has to teach the model how its specific hands work in that world. Everything else is borrowed from the internet.
This is the embodiment frontier. One model, many bodies, one shared brain.
Where things are going
A few patterns are obvious in the 2025–2026 literature. The first is fast-slow hierarchies: Figure AI’s Helix runs a 7B VLM at 9 Hz on top of an 80M visuomotor policy at 200 Hz, NVIDIA’s GR00T N1 splits the same way, and Gemini Robotics formalizes “VLA” and “VLA-ER” (embodied reasoner) as separate models that call each other. It’s Kahneman’s System 1 / System 2, except in PyTorch.
The second is world models as the data substrate. Robot trajectories sit at roughly 1M episodes against LLM-scale ~15T tokens, which is a five-order-of-magnitude data deficit. And generic VLMs lack the physical understanding of the real wolrd dynamics. The emerging fix is to train world models (V-JEPA 2, Genie 3, NVIDIA Cosmos) and use them to hallucinate plausible trajectories at scale. NVIDIA’s GR00T-Dreams blueprint generated 780k synthetic trajectories in 11 hours of wall-clock, which is the kind of multiplier the field needs.
The third is RL post-training. π*₀.₆, GR-RL, and friends now post-train VLAs with reinforcement learning on real-world deployment, picking up 30–50 percentage points over the supervised base. Imitation learning gets the model to a reasonable baseline, but real robustness comes from RL exploration on top of it.
Finally, action tokenization itself has become a research program. FAST applies a DCT to the time axis of action sequences and runs BPE over the coefficients, compressing chunks 10× and training 5× faster than π₀’s diffusion. The action vocabulary is starting to look as engineered as the BPE tokenizers that power LLMs.
The honest cons
Modern VLAs reason like they did a humanities PhD and grasp like a toddler. Moravec’s paradox is alive and well: the same model that interprets “move the apple near the sum of two plus one” cannot reliably insert a USB, and sub-millimeter precision tasks remain brittle even after heavy RL. Most VLAs are also force-blind, since input is RGB and proprioception only, so contact-rich tasks like peg-in-hole and polishing suffer accordingly. Distribution shift is real too; change the camera angle 15 degrees and watch performance go for a toss.
Evaluation is also a mess. The field has 500+ models and 17+ benchmarks, with numbers diverging across forks because everyone subtly tweaks seeds, image resizing, and inference budgets. There is no ImageNet for robots yet.
For driving specifically, chain-of-thought is the most awkward constraint. A 99 ms Alpamayo cycle is fast for a VLA and slow for traffic, and free-form CoT tokens chew that budget. Structured causal reasoning (Alpamayo’s CoC, ORION’s compressed planning token) is the field’s bet on closing the gap between grounding benefit and latency cost.
Conclusion
If the ViT was about turning images into words, and the VLM was about turning images into dialogue, the VLA is about turning images and dialogue into motion. We’ve given the LLM eyes, then a mouth, and now hands. The same Transformer that writes your code can drive your car or fold your laundry, not equally well and not yet without help, but the architecture is uniform and the recipe is clear. The bet for the next decade is whether we can manufacture, in one form or another, the billion robot trajectories we’d need to make this work as well as language models work today.
And now you know. Fin.
{kind=link}