On the cover: Decorative
In our last post, we spoke about how the Vision Transformer (ViT) took the candy away from CNNs. We learned that if you slice an image into patches and flatten them, you can treat an image just like a sentence. And a sequence of pixel-patches becomes a sequence of tokens.
This enables the ViT to look at an image and output a label class_id: 284 (“Siamese Cat”). All this is good, but while ViTs taught computers to “read” images, they are still essentially mute.
Meanwhile, in the building next door, NLP scientists were using Large Language Models (LLMs) like GPT-3 were writing poetry and coding in Python. But they were blind. They had never seen a sunset, only read descriptions of one.
The obvious question asked by researchers around 2021 was, “We have a model that understands vision (ViT) and a model that understands language (LLM). What happens if we introduce them to each other?”
Welcome to the era of Vision-Language Models (VLMs). This is the story of how AI learned to see and speak at the same time.
The Problem: The Tower of Babel
You might think, “Just glue the ViT to the LLM and be done with it.”
It’s not that simple. Even though both models use the Transformer architecture, they speak completely different mathematical languages.
- The ViT spits out vectors that represent edges, textures, and shapes.
- The LLM spits out vectors that represent grammar, logic, and vocabulary.
If you feed ViT output directly into an LLM, it looks like gibberish. It’s like trying to plug a Nintendo cartridge into a toaster. We needed a “Rosetta Stone” - a guide/projector that bring the two worlds together.
The Matchmaker (CLIP)
Before we could get models to chat about images, we had to get them to agree on what images were. The breakthrough came from OpenAI in 2021 with CLIP: Learning Transferable Visual Models From Natural Language Supervision.
CLIP (Contrastive Language-Image Pretraining) wasn’t built to generate text. It played a massive game of “Match the Caption.” Imagine you have a batch of N images and N text captions. The images are run through an Image Encoder (like a ViT), while the texts are run through a Text Encoder (like a mini-BERT). The goal: The model must figure out which text belongs to which image.
** Fun Side: CLIP started off with CNNs as encoders (in the original paper) and later adopted ViTs in most implementations of recent times.
Mathematically, it maximizes the dot product (similarity) between the correct image-text pairs and minimizes it for the incorrect ones. This forces the model to learn a shared embedding space. Essentially,
\[\frac{e^{\text{similarity score of a correct pair}}}{\sum_{\text{all pairs}}e^{\text{similarity score of pairs}}}\]specifically,
\[\mathbb{L} = \sum_{i=1}^{|\mathbb{B}|} \log \frac{e^{x_i^\top y_i / \tau}} {\sum_{j=1}^{|\mathbb{B}|} e^{x_i^\top y_j / \tau}} + \sum_{i=1}^{|\mathbb{B}|} \log \frac{e^{x_i^\top y_i / \tau}} {\sum_{j=1}^{|\mathbb{B}|} e^{x_j^\top y_i / \tau}}\]where $x_i$ is an image feature vector and $y_j$ is a text feature vector, $\mathbb{B}$ is the mini-batch size of images and texts, and $\tau$ is a temperature parameter.
The loss is computed twice, one for every image and one for every text.
- Image -> Text
- Text -> Image
Softmax forces every image to compete against all other texts in the batch.
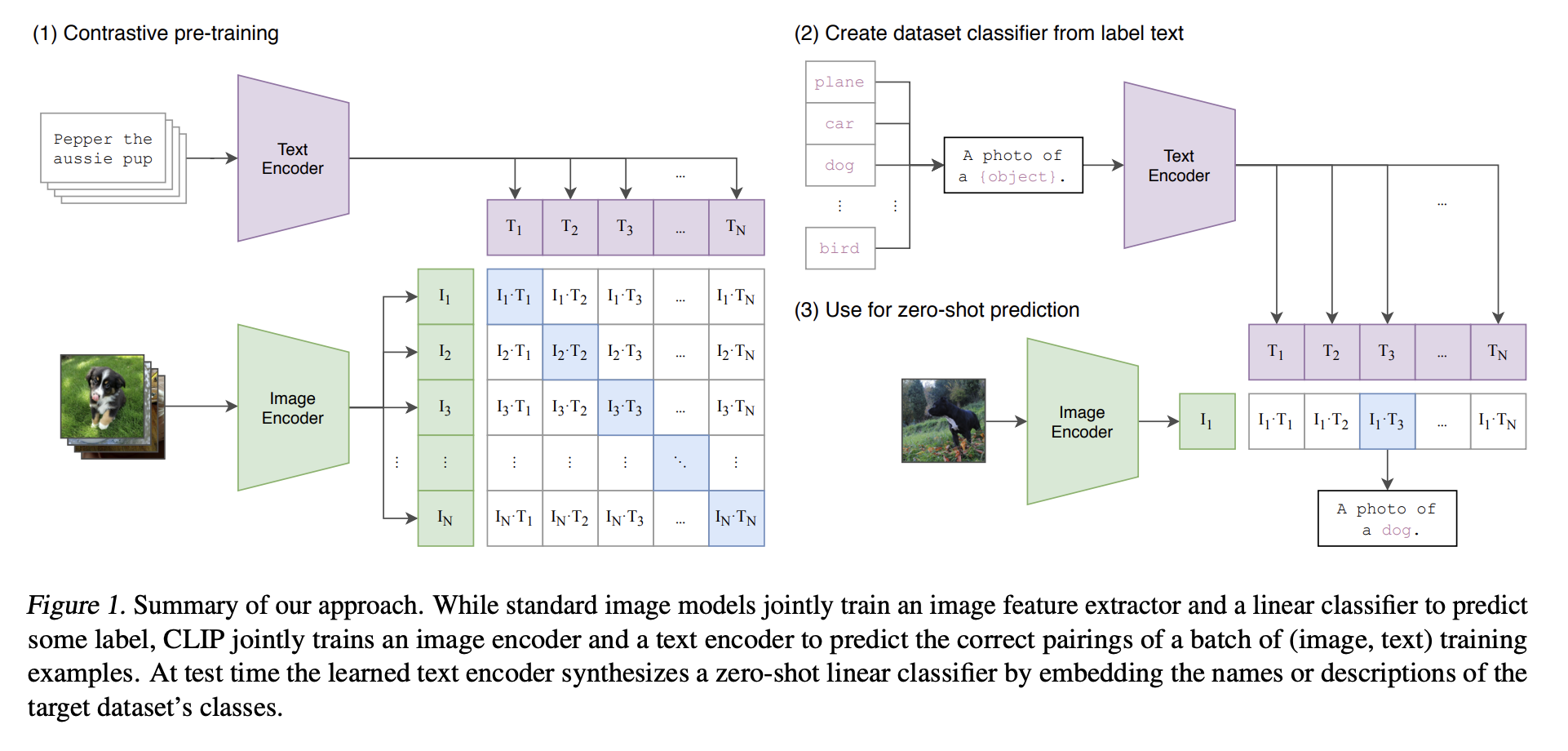 Figure 1: CLIP architecture. Source: CLIP paper
Figure 1: CLIP architecture. Source: CLIP paper
Thanks to CLIP, the vector for “cat” (text) and the vector for a picture of a cat (image) pointed in the same direction. The barrier between image and language was broken.
CLIP’s softmax loss had a limitation: it forced captions to compete within a batch, requiring large batch sizes and careful curation. Google’s SigLIP improved this by replacing softmax with sigmoid loss, treating each image-text pair as a simple binary classification (match or no match). This made training more efficient and stable.
But here’s the key limitation: both CLIP and SigLIP are two-tower models. They learn “this whole image matches that whole sentence” but not “this part of the image explains this part of the sentence.” No token-level interaction. No compositional reasoning. Two towers, no bridge. Which brings us to actual conversational/generative VLMs.
The Conversationalist
CLIP was great at matching, but it couldn’t write you a Shakespearian style poem about a cat picture. To do that, we needed Generative VLMs. This generation of models used cross-attention to fuse modalities inside Transformers.
The current standard architecture for VLMs is quite simple. It’s essentially a “Frankenstein” model stitched together from three parts:
\[Tokens_{vision} = P(V(I)) \\ Tokens_{text} = E(T) \\ Output = LLM(Tokens_{vision}; Tokens_{text})\]Where:
- $V(I)$ = Vision encoder
- $P$ = Projection layer
- $E(T)$ = Tokenizer + Embeddings
- $LLM$ = Language decoder
So essentially,
-
The Eyes (Vision Encoder) We take a pre-trained Vision Transformer (usually CLIP’s vision encoder or Google’s SigLIP). We pass the image through it to get those “patch tokens” we discussed in the last blog. Status during training: Usually Frozen (we don’t want to break the eyes).
-
The Brain (The LLM) We take a pre-trained LLM (like Vicuna, Llama 3, or Mistral). This provides the reasoning, grammar, and world knowledge. Status during training: Frozen initially, then Fine-tuned later.
-
The Translator (The Projector) This is the magic glue. The output of the Vision Encoder might have a dimension of 1024, but the LLM expects an input dimension of 4096. We insert a simple Linear Projection Layer (or a small MLP) that translates “Visualspeak” into “LLMspeak.”
-
The Flow: We concatenate these visual tokens with text tokens. The LLM takes this combined sequence and just predicts the next token, exactly like it always does. It doesn’t even know it’s “seeing” an image; it just thinks it’s reading a very strange language that happens to describe a visual scene perfectly.
Cross-Attention Mechanism
Given:
- Text queries (Q_T)
- Image keys/values (K_I, V_I)
We compute:
\[\text{Attn}(Q_T, K_I, V_I) = \text{softmax}\left( \frac{Q_T K_I^T}{\sqrt{d}} \right)V_I\]Now text tokens attend directly to visual tokens. Language can “look” at pixels. This is multimodal grounding part. If you look at the LLaVA paper, you’ll see the training is split into two distinct stages. This is crucial for stability.
Stage 1: Vision Pre-training
The goal of this stage is to teach the Vision Encoder to see the world. Using image-caption pairs (e.g., “A cat on a mat”) as training data, only the Vision Encoder learns during this phase while the Projector and LLM remain frozen. As a result, the Vision Encoder learns to see the world.
Stage 2: Vision Language Alignment
The goal of this stage is to teach the “Projector” to translate. Using simple image-caption pairs (e.g., “A cat on a mat”) as training data, only the Projector learns during this phase while the Vision Encoder and LLM remain frozen. As a result, the LLM stops seeing the image tokens as noise and starts recognizing them as concepts.
Stage 3: Visual Instruction Tuning
The goal of this stage is to teach the model to follow instructions and act like a chatbot. Using complex conversations as training data (e.g., User: “What is unusual about this image?” Assistant: “The man is ironing a sandwich, which is highly atypical…”), both the Projector and the LLM learn during this phase. As a result, the model can reason, count, and explain visual data.
The Evolution:
There were many variants of VLMs proposed in the research community. Each took a different approach to the same core problem: how to make vision and language work together.
BLIP and BLIP-2 (Bootstrapping Language-Image Pre-training, SalesForce 2022-23): BLIP and BLIP-2 introduced the concept of a Querying Transformer (Q-Former) that sits between the frozen vision encoder and frozen LLM. Instead of directly projecting image tokens, the Q-Former learns a set of learnable query tokens that extract the most relevant visual features. This lightweight module (188M parameters) acts as an information bottleneck, compressing visual information while keeping both the vision encoder and LLM frozen. The result? You can swap different LLMs without retraining the entire model.
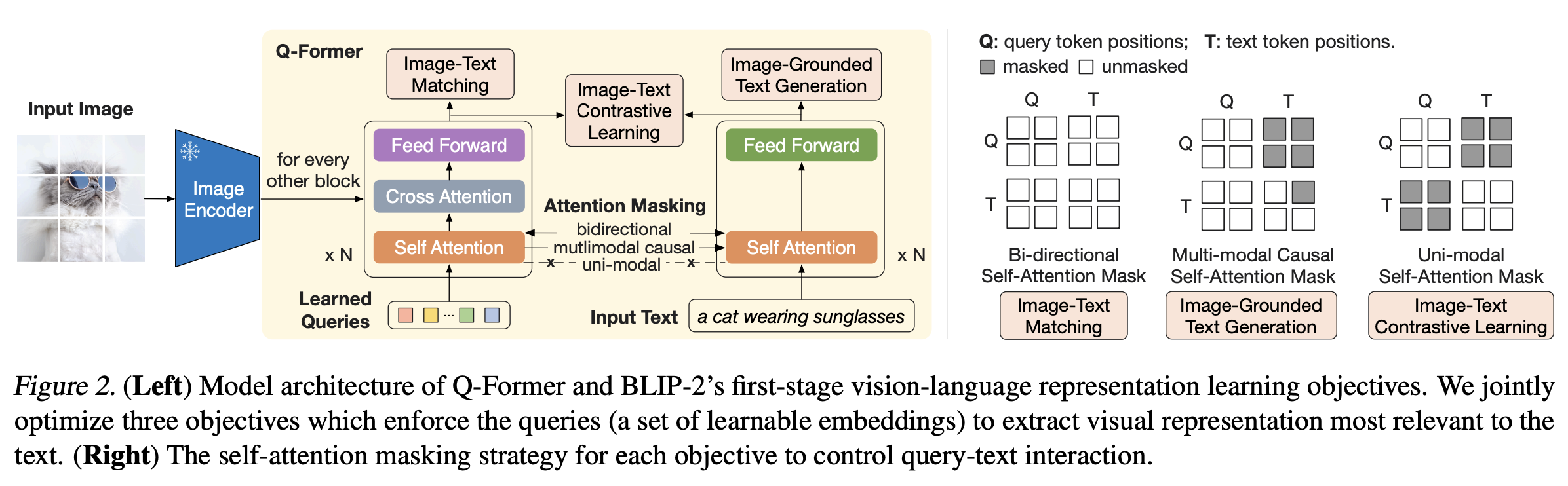 Figure 2: BLIP-2 architecture. Source: BLIP-2
Figure 2: BLIP-2 architecture. Source: BLIP-2
Flamingo (DeepMind, 2022) Flamingo pioneered the idea of interleaved multi-image inputs. Rather than just handling one image at a time, Flamingo can process sequences like: “Here’s photo 1, photo 2, and photo 3. What changed?” It introduced Perceiver Resampler modules and gated cross-attention layers that allow the LLM to attend to visual information only when needed. This architecture enabled few-shot learning-show it a couple of examples, and it adapts on the fly.
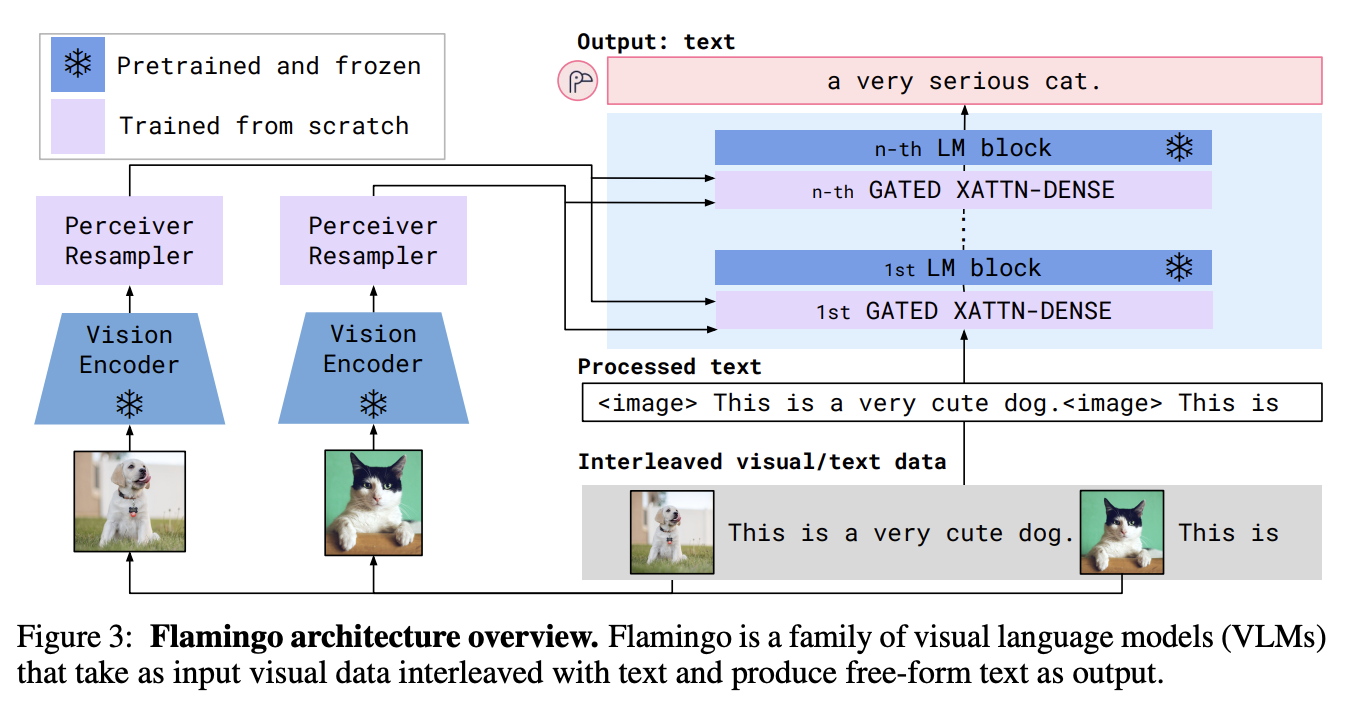 Figure 3: Flamingo architecture. Source: Flamingo
Figure 3: Flamingo architecture. Source: Flamingo
GPT-4V and Gemini (OpenAI & Google, 2023) marked the shift to natively multimodal architectures. Unlike the “stitched together” approach, these models were trained from scratch with vision and language interleaved from the beginning. The exact architectures remain proprietary, but the performance leap was clear: these models could handle complex spatial reasoning, read dense tables, and even solve geometry problems from textbook diagrams.
LLaVA-NeXT and Variants (ByteDance, 2024) LLaVA-Next pushed the boundaries of open-source VLMs by introducing dynamic high-resolution processing. Instead of downsampling images to fixed sizes (like 336×336), these models use adaptive tiling-splitting high-res images into multiple crops and processing them in parallel. This allowed models to read small text in screenshots and understand fine-grained details that earlier VLMs would miss.
 Figure 3: LLaVA-Next tasks. Source: LLaVA-Next
Figure 3: LLaVA-Next tasks. Source: LLaVA-Next
DeepSeek-VL and variants (DeepSeek, 2024): Deepseek-VL introduced a hybrid vision encoder architecture that combines both low-resolution semantic features and high-resolution detail features. Instead of relying solely on a single ViT, DeepSeek-VL uses a dual-stream approach: a SigLIP encoder for semantic understanding and a SAM (Segment Anything Model) encoder for fine-grained visual details. This hybrid approach allowed the model to excel at both holistic scene understanding and precise visual grounding tasks, achieving competitive performance with significantly fewer training tokens compared to other open-source alternatives. [Deepseek-VL2] then built on top of this with by dividing images into multiple tiles dynamically and achieves stronger fine-grained understanding capabilities compared to DeepSeek-VL.
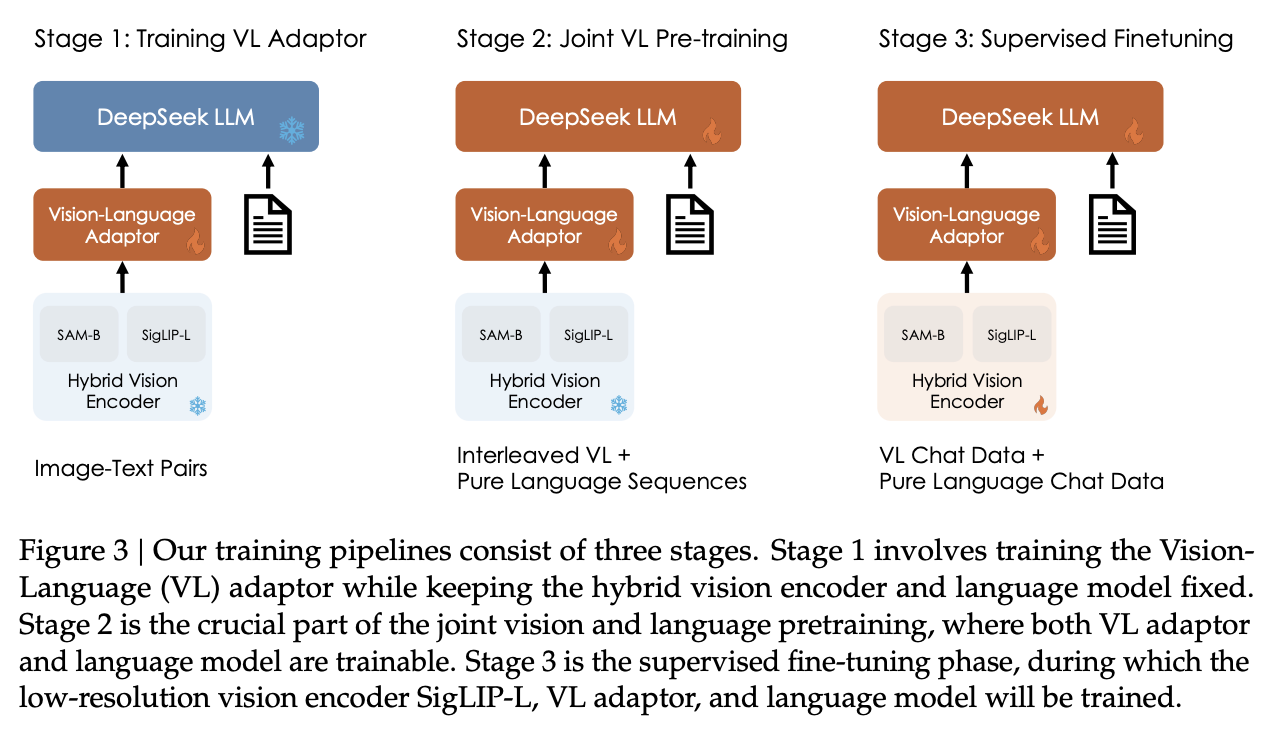 Figure 3: Deepseek-VL training. Source: Deepseek-VL
Figure 3: Deepseek-VL training. Source: Deepseek-VL
The common thread? The community moved from “frozen components glued together” toward end-to-end trainable systems that truly understand the interplay between pixels and words. We went from models that could match images to captions, to models that can debug your code by looking at an error screenshot.
Why This Matters: The End of “Just Seeing”
We are moving away from specific tools. We used to have one model for “Is this a hotdog?” and another for “Read this receipt.”
VLMs are generalist agents.
- You can show them a picture of your fridge and ask for recipes.
- You can show them a screenshot of code error logs and ask for a fix.
- You can show them a dashboard and ask for a summary of trends.
Why do VLMs scale so well? Because language is compressed human knowledge. Every caption encodes: Physics, Culture, Intent, Affordances, Causality. “A chair” is not pixels. It is: “Something you can sit on.” That’s functional semantics. VLMs learn affordances, not just appearances.
OCR and Document Understanding
Traditional OCR was a brittle pipeline that would panic at the sight of rotated text or a doctor’s handwriting. Specialized VL-OCR models like Deepseek-OCR don’t extract text as a preprocessing step-they understand text as part of the image. This is completely different from the cascased pipeline of detection and recognition stack that were previously used. Checkout the OmniDocBench for a comprehensive evaluation of VL-OCR and VLM models.
Generalist VLMs like Qwen3-VL or Gemini2.5-Pro? They just read it. Show them a code error screenshot, and they don’t just OCR the stack trace; they debug it. Show them a receipt, and they know what’s a subtotal versus a tip (finally, someone who gets restaurant math). The spatial reasoning and semantic understanding happen in one shot. This is why VLMs can read memes, parse scientific papers with equations, and survive your handwritten notes.
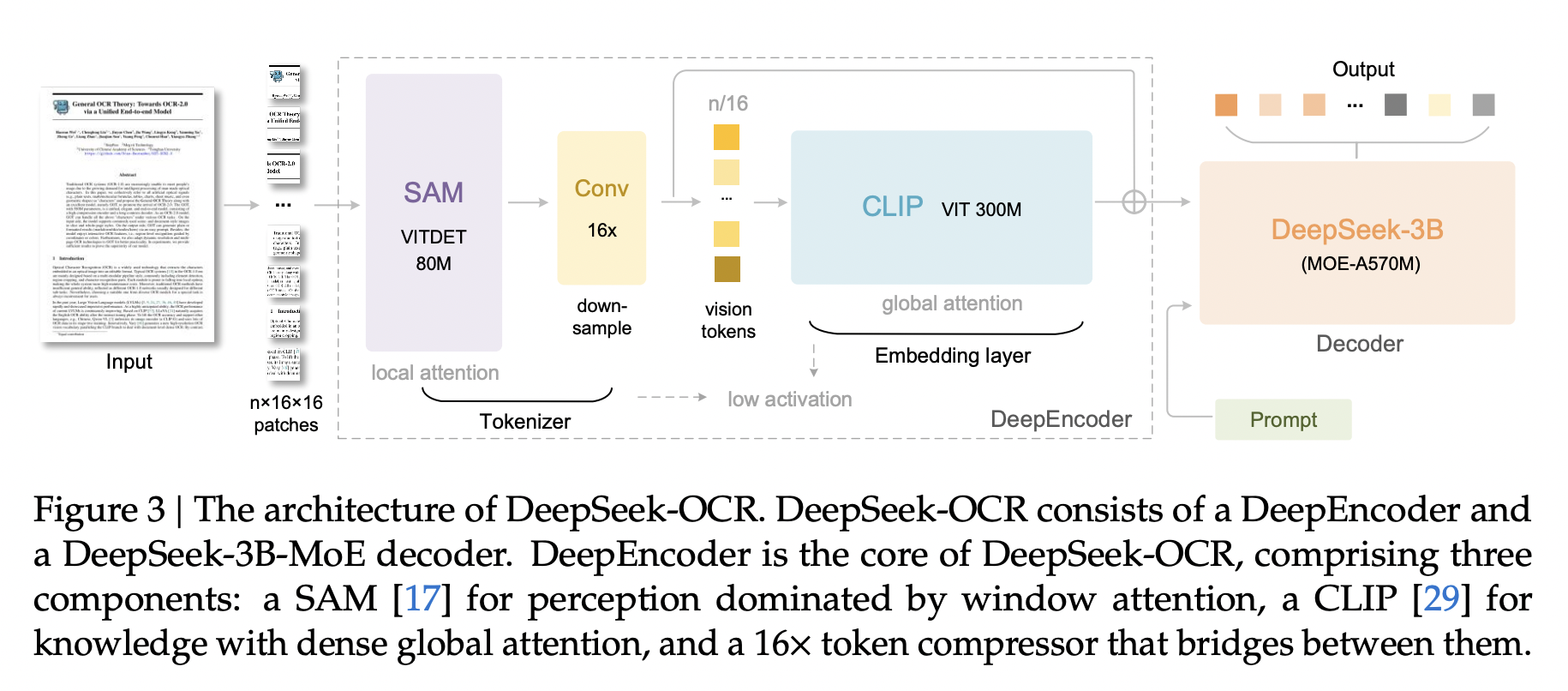 Figure 3: Deepseek-OCR architecture. Source: Deepseek-OCR
Figure 3: Deepseek-OCR architecture. Source: Deepseek-OCR
Video Understanding
Videos are just images with a time dimension. Early approaches treated them like flipbooks; run the VLM on each frame separately and pray. This missed the plot. Literally.
Modern VLMs like Gemini 1.5 can watch up to an hour of video by treating frames as an extended sequence of visual tokens. The key insight: if LLMs can handle 1 million token contexts, why not feed thousands of video frames? Now the model can answer “What happened before the person fell?” or “How many times did the cat knock things off the table?” (critical research). Attention mechanisms capture temporal dependencies naturally; later frames attend to earlier ones, learning cause and effect. We went from “what’s in this frame?” to “what just happened and why?”
The Reality Check: Limitations of VLMs
For all their power, VLMs aren’t perfect: they’re brilliant idiots with expensive taste. They’re only as good as their training data (garbage in, garbage out, now with billions of parameters), which means they can confidently perpetuate biases and stereotypes like a problematic uncle at Thanksgiving.
They’ll miss sarcasm entirely (a VLM might describe the “This is fine” dog meme as just “a dog in a burning room” without catching the existential dread). They excel at describing what they see but stumble on why - sure, that’s a person with a trophy, but understanding they just won their first Olympic medal after years of injury? That’s deep reasoning territory they haven’t conquered yet.
Oh, and they’re computationally ravenous—not everyone has a data center in their pocket, so deploying them on edge devices means brutal trade-offs between speed and accuracy. Finally, keeping visual and textual outputs consistent across dynamic inputs (like video) is like herding cats: the model might nail frame 1 but completely contradict itself by frame 100. TL;DR: VLMs are powerful but flawed, like giving a toddler a PhD.
Conclusion
If the Vision Transformer was about turning images into words, the Vision-Language Model is about turning images into dialogue.
We have effectively given LLMs eyes. By simply projecting visual vectors into the language space, we tricked the text model into hallucinating a vision system. And it works beautifully.
The future isn’t just “Computer Vision” anymore. It’s Multimodal AI.
And now you know. Fin.
{kind=link}