On the cover: Midjourney’s creation for the prompt “Sun Goddess artful”
We saw how we could train a generative diffusion model in the previous post. But what fun is it if you can’t generate something of your choice. Welcome to guidance for diffusion models. There are several variants of guidance to diffusion models and these have evolved and improved over time. In this post I will take you through these variants chronologically. Towards the end we will also discuss the idea behind some of the popular diffusion models.
Class conditional models
This concept was introduced in 2021 by OpenAI authors in the paper Diffusion Models Beat GANs on Image Synthesis. Let’s say we trained our diffusion model with images from a traditional dataset like ImageNet. We can essentially provide the class label embedding as an additional input to the our model. This makes our mean distribution of samples conditional on class labels: $\mu(x_t, t)$ into $\mu(x_t, t | y)$. In this paper, they use what they called the Adaptive Group Normalization layer:
\[AdaGN(h,y) = y_s GroupNorm(h) + y_b\]where, $h$ is intermediate activations of the residual block and $y = [ys, yb]$ are the linear projection of the timestep and class embedding. Problems with this is that it produces incoherent samples.
Classifier guidance
The authors of the same paper also found that providing explicit guidance improves the performance of the above model and hence introduced classifier based guidance. In this case during training, we train a classifier on noisy images $p_\theta(y \vert x_t)$ sampled from the same dataset (ImageNet with added with noise). During sampling, we perturb the mean by gradient of the classifier:
\[\hat{\mu_\theta}(x_t \vert y) = \mu_\theta(x_t \vert y) + s . \Sigma_\theta(x_t \vert y) \nabla_{x_t} \log p_\theta(y \vert x_t)\]where $s$ is the gradient scaling factor which influences the amount of guidance. Increasing $s$, increases sample quality at the cost of diversity.
 Figure 1: Effect of gradient scaling factor on images of Corgi
Figure 1: Effect of gradient scaling factor on images of Corgi
Essentially, we combine the score estimate of a diffusion model with the gradient of an image classifier in order to provide guidance. Problem is that this sometimes provides incoherent images like some of the pictures above.
Classifier free guidance
In so far we have been dealing with providing guidance with classifiers. However it is cumbersome to train a seprate classifier. Also, using classifier gradients resemble GANs and no wonder they perform well on the traditional generative metrics such as FID score. But what if the model itself is capable of guiding itself? Yes, researchers from Google introducted the Classifier Free guidance in 2021 again that doesn’t require a separate classifier to be trained. During training, we jointly train an unconditional diffusion model $\epsilon_\theta(x_t \vert \phi)$ (just add a null label or $y=0$ instead of class label) in addition to the class-conditional diffusion model $\epsilon_\theta(x_t \vert y)$. During sampling, we extrapolate the output of the model:
\[\hat{\epsilon_\theta}(x_t \vert y) = \epsilon_\theta(x_t \vert \phi) + s . (\epsilon_\theta(x_t \vert y) - \epsilon_\theta(x_t \vert \phi))\] Figure 2: Effect of gradient scaling factor on images of Corgi for CF guidance
Figure 2: Effect of gradient scaling factor on images of Corgi for CF guidance
CLIP guidance
In the image above, we have generated an image of Corgi which is a label in the dataset. However, a more natural way to generate images is using text prompts instead of labels. Using class label embeddings restricts the model in generating samples from the same dataset they are trained on and there is a dependency on class labels as input. Enter CLIP (Contrastive Language Image Pre-training) embeddings which is trained on millions of image caption pairs from the internet. CLIP uses a contrastive cross-entropy loss that encourages a high dot-product between image and caption embeddings that match: $f(x) . g(c)$. However, unlike Classifier Free guidance, here one needs to train an additional noisy CLIP model.
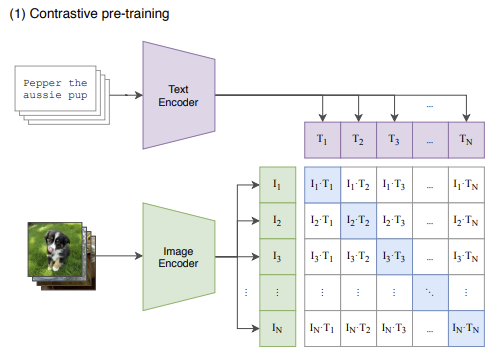 Figure 3: Training of CLIP model. CLIP jointly trains an image encoder and a text encoder to predict the correct pairings of a batch of (image, text) training examples
Figure 3: Training of CLIP model. CLIP jointly trains an image encoder and a text encoder to predict the correct pairings of a batch of (image, text) training examples
In this case, we train a CLIP model on noisy image caption pairs and during sampling, we perturb the mean by gradient of the classifier:
\[\hat{\mu_\theta}(x_t \vert c) = \mu_\theta(x_t \vert c) + s . \Sigma_\theta(x_t \vert c) \nabla_{x_t} (f(x_t) . g(c))\]where $f(x_t)$ is the image encoder, $g(c)$ is the caption encoder of the training noisy CLIP model.
Text guidance
What about generic text prompts? We can use a Transformer to convert the tokens into embeddings and pass it to the model in the place of class embeddings. But how does this work? We can concatenate the text embedding to the attention context at each layer.
\[\hat{\epsilon_\theta}(x_t \vert y) = \epsilon_\theta(x_t \vert c) + s . (\epsilon_\theta(x_t \vert y) - \epsilon_\theta(x_t \vert c))\]where $c$ refers to the text (caption) embedding.
GLIDE
GLIDE refers to Guided Language to Image Diffusion for Generation and Editing. This paper from OpenAI essentially compares Classifier Free (CF) vs CLIP guidance for large diffusion models: 3.5 B parameter text-conditional diffusion model at 64 × 64 resolution and a 1.5 B parameter text-conditional upsampling diffusion model to increase the resolution to 256 × 256. Prefers CF guidance + text embedding using Transformers as it performs the best.
They also experiment with Inpainting which involves modifying parts of the image and generating those according to text prompts. This involves:
- During fine-tuning, random regions of training examples are erased
- Remaining portions are fed into the model along with a mask channel
 Figure 4: Inpainting examples of GLIDE; second image is exemplary of the powerfullness of these models which produces Corgi in artistic style in alignment with the rest of the picture
Figure 4: Inpainting examples of GLIDE; second image is exemplary of the powerfullness of these models which produces Corgi in artistic style in alignment with the rest of the picture
DALL-E2
DALL-E2 (which is a play on the words Salvador Dali (famous Spanish artist) and WALL-E (name of the robot in the famous movie)) is the paper that earned OpenAI its fame. It’s an improvement on their previous work GLIDE. Note that DALL-E paper didn’t have diffusion models, rather it was a zero-shot text-to-image generation by training an autoregressive transformer.
The idea behind DALL-E2 is that given a text prompt $y$, you need to be able to sample images $x$ through the conditional model $p(x \vert y)$. One can re-write this function as a product of a decoder $p(x \vert z_i,y)$ and a prior $p(z_i \vert y)$ where $z_i$ is the CLIP image embedding of the image $x$. Both the prior and decoder can be separate diffusion models.
\[p(x \vert y) = p(x \vert z_i,y) * p(z_i \vert y)\] Figure 5: Interpolating from Van Gogh’s Starry night to a picture of Corgis
Figure 5: Interpolating from Van Gogh’s Starry night to a picture of Corgis
There are several implications of having an encoder decoder architecture, some of which are:
- Model is non-deterministic so one can generate multiple images with the same text prompt unline GLIDE where you can get one image per caption
- Produces semantically similar output images; so one can modify images by moving in the direction of any encoded text vector
- Interpolate between input images by inverting interpolations of their image embeddings
- Con: confuses objects and attributes since the CLIP model in itself doesn’t give importance to this during training
 Figure 6: Attribute and object confusion of DALL-E2; DALL-E2 is also called unCLIP since it decodes CLIP image embeddings
Figure 6: Attribute and object confusion of DALL-E2; DALL-E2 is also called unCLIP since it decodes CLIP image embeddings
Imagen
This is a model from Google that was released as a competitor to DALL-E2. They suggest to just use a large pre-trained model to extract text embeddings like CLIP, T5, BERT or GPT as more power, better representation. They also perform successive upscaling of their models in order to super-resolution the sampled images.
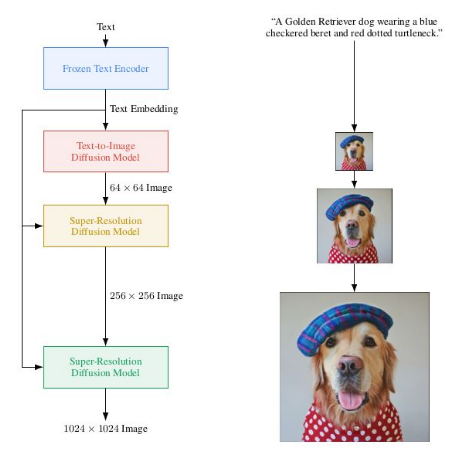 Figure 7: Imagen’s upsampling architecture composed of multiple diffusion models
Figure 7: Imagen’s upsampling architecture composed of multiple diffusion models
Stable Diffusion
This was a model released by a London based startup called Stability AI whose tagline is “AI by the people, for the people”. Noble indeed. The main problem they addressed is that training diffusion models is computationally expensive and not everyone owns large compute power and multiple GPUs like Google or OpenAI.
Their solution was to use the latent space for training, hence they introduced the Latent Diffusion Models (LDMs). This model is exactly the same as the regular diffusion model, except that it uses an autoencoder for encoding the image into the latent space, letting the forward and reverse diffusion training to happen there then decoding the embeddings back to the pixel space.
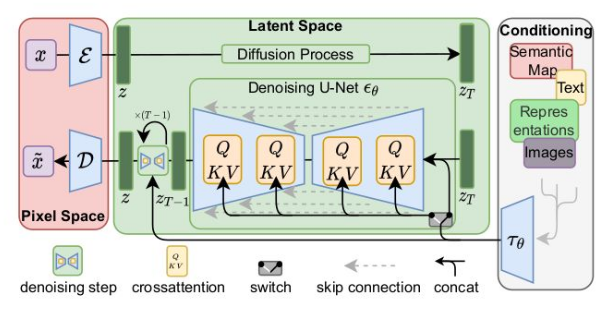 Figure 8: Latent diffusion model where forward and reverse diffusion happens in the latent space
Figure 8: Latent diffusion model where forward and reverse diffusion happens in the latent space
Diffusion models have garnered a lot of attention from the media recently due to the realism of the generated images. This also brings in risks such as generation of deceptive content and ethical concerns such as misappropriation of credit to artists. Hence these require careful regulation of these models starting with filtering and debiassing the dataset that these models are trained on.
Most recently there are models that focus on video generation such as Google’s Imagen video and Meta’s Make-a-video. Do check them out! This makes me think that we’re not far from an entire movie being generated by AI just from a novel. What an exciting time to be alive! See you soon :)
{kind=link}