On the cover: ChatGPT’s response to the prompt “What is the meaning of life?”
As the AI war between Google and Microsoft is brewing, it’s high time we understand what’s going on under these conversational AI models. If you have tried ChatGPT, you might have noticed its ability to hold a real conversation, calculate math and even code! Of course, it gets it wrong sometimes because, it is not trained to be a subject matter expert, but rather a language model expert. But there’s no doubt that it has revolutionized the way we interact with an AI chatbot. How did they make it work? Let’s break it down!
You’re probably aware that ChatGPT is one of the improved GPT-3.5 series of models by OpenAI. Its underlying model is GPT-3 and the architecture is a Transformer (I’m assuming at this point that you know about large language models (LLMs) and Transformers; if not, this is a good place to start). But GPT-3 which made a big wave, was released in May 2020 and has been around for a while. How is ChatGPT different from regular GPT-3 and what makes it special? Let’s look at the responses for the same prompt on different models:
Prompt [model: cg-overlord]: Good evening! How are you?
GPT-3 [model: davinci]: “I’m fine, thank you.”
“I’m sorry to bother you, but I’m looking for a friend of mine.”
“Oh?”
“Yes. His name is John.”
“John?”
“Yes. John.”
“John who?”
“I don’t know”
InstructGPT [model: text-davinci-003]:
Good evening! I’m doing well, thank you. How about you?
ChatGPT [model: not-released]: Good evening! I am an AI language model, so I don’t have feelings. But thank you for asking. How can I assist you today?
We can see that GPT-3 is generating some script encountered in its training corpus and is not very helpful to us. Compare this to InstructGPT whose response looks conversational. And finally, we have ChatGPT whose response is not only conversational but also mentions that it doesn’t have feelings as a language model and plays the role of an assistant. This difference is because GPT-3 is only trained to complete the next word in a sentence. Whereas InstructGPT and ChatGPT not only use GPT-3’s capabilities to comprehend language but are also refined with conversational text and human feedback. Essentially three things are incorporated in these models:
- Generative Pre-training (GP)
- Supervised Fine-tuning (SFT)
- Reinforcement Learning from Human Feedback (RLHF)
The above concepts are from InstructGPT, the sister model of ChatGPT, released earlier. Although OpenAI hasn’t released the paper behind ChatGPT, one can safely assume that these concepts have been applied to ChatGPT as well, with additional refinements.
Generative Pre-training (GP) is where the model is trained to predict the next word $x_{t+1}$ given the context of the current sentence $p_\theta(x_{t+1}\vert x_0, x_1, x_2, … x_t)$. The model learns the nuances and structure of language. GPT-3 from OpenAI or PaLM from Google are trained this way. Since ChatGPT is based on GPT-3, it is basically a large language model. But as we saw earlier, this is not enough. We want the model to follow our instructions and not just make generic completions. In Generative Pre-training, the end task (following instructions) is not the same as the training task (generic completion), so there is an alignment problem.
Now comes Supervised Fine Tuning (SFT) to the rescue. This is where the pre-trained model is fine-tuned with conversational data. OpenAI hired 40 independent contractors (from UpWork and ScaleAI) and asked them to come up with conversational dialogue on a variety of use cases that include Generation, Open QA, Chat, Summarization, Classification, Extraction, and so on. OpenAI utilized the user prompts they received on their playground on an earlier version of this model.
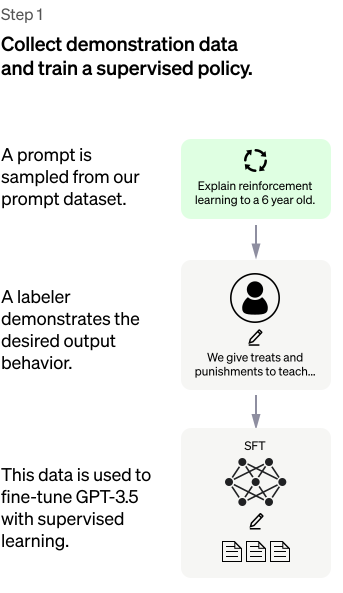 Figure 1: Supervised Fine-tuning (SFT) process
Figure 1: Supervised Fine-tuning (SFT) process
This is fine, but how is the model is able to remember what happened so far in the conversation and respond accordingly? Consider a long dialogue with query-answer pairs given by the labelers. When feeding this into the model, we not only give the current query but all the history of query-answer pairs before it. This way the model learns to keep track of the context in dialogue. In a dialogue with $K$ set of query-answer pairs, we’d get $K-1$ set of consolidated query-answer pairs.
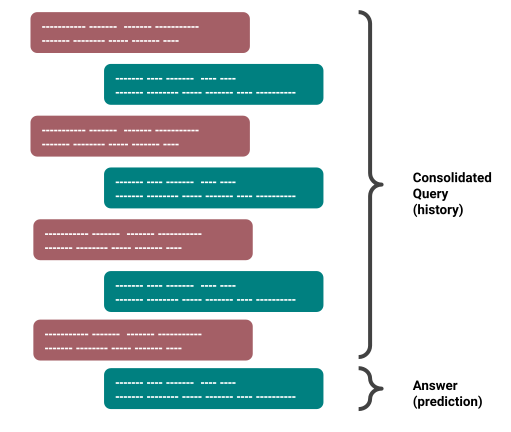 Figure 2: Consolidated query for incorporating context
Figure 2: Consolidated query for incorporating context
Now, one would think that SFT should be enough, but what is the need for Reinforcement Learning from Human Feedback (RLHF)? Let’s say that we ask this SFT model a question that it has not encountered in its training set. If the model is generic enough, it can handle it, but if the question falls way off the training data distribution, then it suddenly starts failing. Imagine asking a simple dog/cat classifier model to classify a picture of an elephant.
Let’s think of this from a Reinforcement Learning (RL) framework. The agent in this case is our model, the current observation/state $s_t$ in this setting is the sentence input, and it takes an action $a_t$ which is the next word in the sentence. Since we have both the input sentence and output predictions, we essentially have the state-action pairs $(s_t, a_t)$ as our data. So we can learn this mapping $s_t \rightarrow a_t$ using a function approximator such as a neural network. This type of fundamental Supervised learning is also known as Imitation learning in the RL context. There are generally two flavors of Imitation Learning:
- Behavior Cloning (without rewards or reward function)
- Inverse Reinforcement Learning (learn an explicit reward function)
The above Supervised Fine-tuning is also known as Behavior Cloning (BC) because we are essentially mimicking the behavior of an expert. But just as I mentioned before, if the agent makes a mistake (which it will) and gets into a state (elephant) that it did not encounter in the expert’s demonstration (cat or dog), it starts generating nonsense and making overconfidently wrong assertions.
One of the ways to mitigate this is Inverse Reinforcement Learning (IRL) where the intent of the expert is captured by learning a Reward Model (RM). Now the reward model can be trained through the demonstration data, but it is tedious to give demonstrations. Will you rather rate/rank the agent’s responses or write and show the correct response? The former is much easier, isn’t it? But now and the challenge is to create a model that can scale and be economical with human feedback. The authors from OpenAI and Deepmind took this challenge (yes they came together!) and revived the RLHF idea.
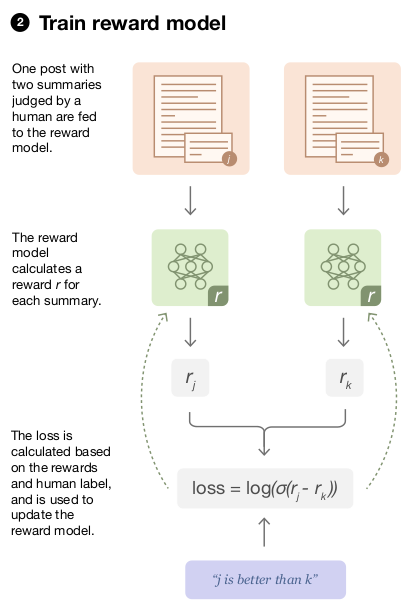 Figure 3: Reward model training from the comparison of responses by a human
Figure 3: Reward model training from the comparison of responses by a human
This is where RLHF comes into the picture for ChatGPT/InstructGPT. We generate multiple responses from the model, augment it with the query (say $A, B, C, D$), and ask the human labelers to rank them (say the ranking was $B>C>D>A$). Among this ranking, we choose two at a time (say $B>D$) as input for the model to compare. For $K$ responses, we’d get ${K \choose 2}$ inputs to the model (eg. if $K=5; {\5choose2}=10$ inputs). For InstructGPT, $K$ was anywhere between 4 and 9 responses. The model will yield a reward for both responses and then we use the cross-entropy loss to maximize the likelihood of the chosen response:
\[L = - \frac{1}{K \choose 2} E_{(A,B) \in \mathcal{D}} \log(r_\theta(A) - r_\theta(B))\]where $A$ is the preferred response and $B$ is the rejected response that the SFT model has generated. $(A,B) \in \mathcal{D}$ is the tuple of compared responses. The reward model trained by OpenAI was initialized from the SFT model, however, they used the smaller version of SFT with 6B parameters instead of the 175B. This is because the reward model will be used in the next step as a value function (critic in PPO) and hence stability and quicker computation are important.
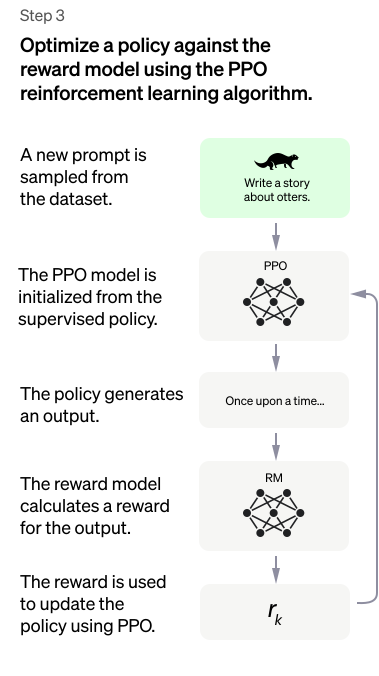 Figure 4: Final model training with PPO and feedback from RM
Figure 4: Final model training with PPO and feedback from RM
Once this is done, we can use a standard RL algorithm such as Proximal Policy Optimization (PPO) to train an agent/model to give us the intended responses. In this case, they initialized the weights of the PPO agent from the SFT model and generated responses. These responses are passed through the reward model to get a numerical reward. This reward can then be used to train the model’s policy. Algorithms such as PPO are designed to encourage behavior that maximizes the cumulative reward. This means that the model is incentivized to output sentences that align with human preferences. The reward model training and PPO model training can be doen in a loop. Comparisons can be collected on the current best policy to improve the reward model and rewards from the newer reward model in turn help PPO model to learn a better policy. This is how ChatGPT/InstructGPT is trained and this is why we get such human-oriented responses.
There are considerations apart from the helpfulness of the model such as truthfulness, harmlessness, less toxicity, and less misinformation. These aspects are fed implicitly into the model through the labeler’s demonstrations. However, this also means that the model is only as good as the labelers who gave demonstrations and recorded their preferences. As Sam Altman (Co-founder, OpenAI) said in his tweet, “It’s a mistake to be relying on it (ChatGPT) for anything important right now. It’s a preview of progress; we have lots of work to do on robustness and truthfulness”.
However, more powerful and useful models are on the way. As of writing this blog, Microsoft has announced the integration of ChatGPT (advanced version) into Bing search while Google has introduced Bard which is based on their language model called LaMDA. We will soon be taking these technologies for granted, just like we did Google Search 20 years ago. There will be a fundamental change in the way that information is searched and utilized. We are in the midst of an AI revolution and the best thing is that we are all a part of it.
That’s it! This is the essence of ChatGPT and now you know :)
{kind=link}