On the cover: Screenshot from the movie “Ron’s gone wrong” where a kid teaches his pet robot how to behave socially
The term “RLHF” or Reinforcement Learning from Human Feedback has become popular due to Conversational AI models like ChatGPT. How did Reinforcement Learning (RL), a branch that deals with agents and rewards find its way into Natural Language Processing (NLP)? Well, let’s find out!
Consider Large Language Models (LLMs): these have undoubtedly become the holy grail of NLP. Just by trying to predict the next word in a sentence, on a sizeable generic corpus from the internet, these models have developed a fundamental understanding of natural language as humans do. Instead of training separate models for every task, people started finetuning these LLMs for a variety of tasks including summarization, translation, question answering, and so on. These finetuned LLMs beat the models that were trained from scratch and thus became the standard practice in NLP. One thing to note is that even in the finetuning task, the underlying work is next-word prediction.
Okay now, let’s think of LLMs from a Reinforcement Learning (RL) framework. In any RL setting, there is a notion of an agent and an environment. The agent is exposed to observations $s_t$, takes an action $a_t$, and gets a reward $r_t$ from the environment. In the task of next-word prediction, the agent is our LLM, the current observation is the sentence input, and the action is the next word in the sentence.
Conversational AI models like ChatGPT uses the base LLM as GPT-3 and are finetuned with conversational data. This is a supervised training, where we have both the input sentence and output predictions. This means that we essentially have the state-action pairs as our data. So we can learn this mapping using a function approximator such as a neural network. This type of fundamental supervised learning is also known as Imitation learning in the RL context. There are two different flavors of Imitation Learning:
- Behavior Cloning (BC)
- Inverse Reinforcement Learning (IRL)
Behavior Cloning
The vanilla Imitation Learning described above is called Behavior Cloning, because the agent tries to imitate an expert’s behavior. In the Behavior Cloning, we learn the policy directly from state-action pairs without any rewards or designing a reward function. In this setting, there are two big problems:
- We assume that the expert’s demonstration data of state-action pairs $(s_0,a_0), (s_1,a_1), (s_2,a_2),…$ are IID (Identical and Independently Distributed) which is not true in this case. Even in ChatGPT, the follow-up questions and answer pairs are not independent of history. It starts to look more like an Markov Decision Process (MDP) right? ;)
- The state distribution in the training dataset follows the expert’s demonstration. However, the state distribution during inference is the one that the agent has generated. The agent’s state distribution could deviate from the expert’s state distribution. When the agent inevitably makes a mistake (nobody is perfect), it starts to encounter states it has never seen before (see diagram below).
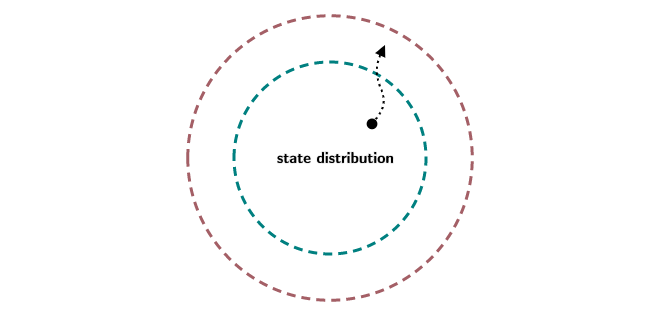 Figure 1: State distribution of expert in teal and agent in brown
Figure 1: State distribution of expert in teal and agent in brown
Because of the IID assumption and the novel state distribution, errors in the model’s prediction start compounding, leading to critical failure! Let’s say you trained an agent to drive a car using Behavior Cloning. The state being the image feed and actions being the steering/acceleration of the car. When the agent starts driving, it might come across an obstacle that makes it take a sharp turn and now it faces the road railing. The agent might not have seen this before, because humans are unlikely to make this mistake. So now it doesn’t know what to do and meets with an accident.
In the case of conversational models trained with Behavior Cloning, they start generating garbage or overconfident stuff to our queries because of these problems. How can we mitigate this? Well, we can query the expert during training to give us the best action for the current policy. We can then iterate the training until the agent policy looks similar to the expert policy. This helps in taking into account the novel states and learning recovery behavior for the agent. In the above example, the agent can avoid accidents if it queries the expert for the right actions to take when it is about to collide.
This method of taking an expert’s guidance during training is called Direct Policy Learning (via Interactive Demonstrator) and it is an improvement on Behavior Cloning. Famous papers in this method are DAgger where all the previous data is collected into one big dataset (data aggregation) and SMILe where the previous policies are combined using a geometric blending (policy aggregation). But here again, you need the expert to give explicit actions during inference many times over, ie., the labelers in OpenAI have to work overtime writing correct responses for every generation from the model. Not ideal.
Inverse Reinforcement Learning
Another way to do Imitation Learning is through Inverse RL. Here, the expert’s intention is captured in a Reward Model (RM). The reward model is essentially trained to predict a scalar reward for a given state-action pair from the expert demonstration data. The reason for calling this Inverse RL is pretty clear: instead of learning an optimal policy from rewards like normal RL, learn the reward first from an expert/optimal policy (state-action pairs). The agent uses these generated rewards from the RM to learn the optimal policy using any known RL algorithm.
Two approaches that took off in this method are the Maximum Entropy IRL where the reward function is estimated by maximizing the entropy of expert policy. And Generative Adversarial Imitation Learning (GAIL) where the generator tries to generate a policy close to the expert and the discriminator evaluates the policy with a reward function (here the discriminator becomes the RM).
IRL works on the assumption that it is possible to demonstrate the desired behavior, but what if:
- demonstration is not possible at all? for example, imagine demonstrating how to do a backflip for a non-humanoid robot
- demonstration is tedious to provide? for example for ChatGPT, we cannot keep providing demonstrations indefinitely
RLHF
If you think about it, it’s much easier to grade an agent’s actions rather than to demonstrate exactly how something is done. A simple good or bad feedback is enough in many cases. This is the core idea behind RLHF. This compelled researchers from OpenAI and Deepmind to come together on this research paper Deep Reinforcement Learning from Human Preferences and they showed that it is possible to economically scale up these techniques to large problems and deep RL systems. The idea for a simple preference feedback itself is not new because the notion of rewards comes with a preference towards a set of actions over others. This preference feedback can be used to learn a reward model (RM) just like before (overall pipeline in the diagram below).
 Figure 2: The RLHF pipeline from OpenAI paper
Figure 2: The RLHF pipeline from OpenAI paper
You might also think as to why not give the agent a direct scalar value instead of preference feedback. Problem is that the scalar rewards vary from person to person. Instead, it is easier to give a preference. Now, how do we train with preference feedback? The probability of preferring one trajectory/response (say $A$) over the other (say $B$) is given by,
\[\begin{aligned} P(A>B) &= \frac{\exp(r_\theta(A))}{\exp(r_\theta(A))+\exp(r_\theta(B))}\\ &= \frac{1}{1+\exp(-(r_\theta(A)-r_\theta(B)))}\\ &= \sigma(r_\theta(A)-r_\theta(B)) \end{aligned}\]where $\sigma(x) = \frac{1}{1+e^{-x}}$ is the sigmoid function. The paper says that this follows from the Bradley-Terry model for estimating score functions from pairwise preferences. This can also be understood in terms of Elo ratings in chess. If you know the Elo ratings of two players A and B, the probability of player A winning over player B is given by,
\[P(A>B) = \sigma_{10}\Big(\frac{Elo(A) - Elo(B)}{400}\Big)\]where $\sigma_{10}$ is the sigmoid function with base $10$ instead of $e$. This is neat isn’t it? Can you guess what the distribution of Elo ratings of all the players in the system? (Hint: think sigmoid). If say $A$ and $B$ are the responses from the model (augmented with the query $Q$), and we prefer $A$ over $B$, then $\mu(A)=1; \mu(B)=0$. We can use the following cross-entropy loss function to train our reward model:
\[\begin{aligned} L &= - \sum_{(A,B) \in \mathcal{D}} \mu(A) \log(P(A>B)) + \mu(B) \log(P(B>A))\\ &= -\sum_{(A,B) \in \mathcal{D}}\log(P(A>B))\\ &= -\sum_{(A,B) \in \mathcal{D}}\log\sigma(r_\theta(A)-r_\theta(B)) \end{aligned}\]In conversational AI models (InstructGPT in particular), the model is made to generate $K$ responses. So we can have $K\choose2$ pairs of comparisons that we can make. Example if the model generates four responses, $A, B, C, D$ and our ranking is $B>C>D>A$, then there are ${4\choose2}=6$ comparisons possible: $B>C$, $B>D$, $B>A$, $C>D$, $C>A$ and $D>A$. The loss function in this case becomes,
\[L = - \frac{1}{K\choose2} E_{(A,B) \in \mathcal{D}} \Big[\log\sigma(r_\theta(A)-r_\theta(B))\Big]\]Once this reward model is trained, we can apply an out-of-the-box RL algorithm such as PPO. If you recall the training process of InstructGPT/ChatGPT from my previous post, it contained three steps:
- Generative Pre-training (GP)
- Supervised Fine-tuning (SFT)
- Reinforcement Learning from Human Feedback (RLHF)
Of these, Supervised Fine-tuning is nothing but Behavior Cloning. This alone did not produce good results for the exact reasons mentioned before. Refining these models further with RLHF techniques made them capable of really following instructions and carrying on conversations. RLHF topped the news once ChatGPT went viral, but these techniques have been around for a while in the domain of NLP. The sequential nature of natural language makes them a great candidate for modeling MDP trajectories that form the basis of RL.
RLHF has become popular because of its ease of use and large performance gains. However, it is not without its shortcomings. The reward model in RLHF can only capture human preferences to a certain extent. Similarly, the so-called “human values” that are implicitly fed to the reward model are only as good as the “human experts” that evaluate the agent’s actions. One can see how these models can be misused simply by training them with malicious intent. There are still a lot of improvements to be made, but we are heading in an exciting direction! The secret sauce of ChatGPT is RLHF and now you know :)
{kind=link}