On the cover: A sample t-SNE representations of final hidden state mean pooled along sequence dimensions of pure loss-centric adaptation of BERT on source(CONLL) vs target(Enron, SciTech) domains. Pure loss centric techniques are found to be harmful to the final performance of the models
This work done at ZyLAB BV. Inc. is presented as the final thesis project for my masters AI at UvA. The abstract of this project is as follows:
Named Entity Recognition on real-life data such as email communications is challenging due to lack of annotations and origins from unseen domains. Unsupervised Domain Adaptation (UDA) techniques can be applied to solve this problem, given an established source domain dataset. With the advent of large scale pre-trained models like BERT (Bidirectional Encoder Representations from Transformers) producing exceptional performance on NLP tasks, there arises a question of capacity of these models to generalize on out-of-distribution data.
Hence in this thesis, we study the effect of joint language modeling and three loss-centric UDA techniques on BERT: Cross-Entropy loss, Wasserstein distance and Maximum Mean Divergence. Pure loss-centric techniques are shown to be detrimental to the downstream task performance as they destroy crucial information. For the combined loss-centric language modeling, it is revealed that a weaker metric such as Wasserstein is desired for adaptation between dissimilar domains (Enron vs CONLL) and a stronger metric such as Cross-Entropy is preferred for similar domains (CBS SciTech vs CONLL 2003).
 Enron email fields excluding the body
The Enron email corpus introduced in consists of internal email messages that were made public by the Federal Energy Regulatory Commission (FERC) during the investigation of Enron scandal. The latest version released on May 17th 2015 2 consists of 517,431 emails from 151 users. Each email consists of several categorical fields like To, From, Cc, Bcc, etc., and also unstructured raw fields like Body and Subject. For our analysis we only consider the body of the email which consists of linguistic text information and ignore other fields, as they mostly contain meta-data (refer Fig. 4.1) which is non-linguistic
and adding them would lead to a noisy data which will disrupt the natural language information that is present in the body. An analysis of the email messages reveals a lot of noisy data even in the email body which includes nested email threads such as “Forwarded By” (in 20.3% of emails), “Original Text” (in 14.2% of emails), residual embedded fields like “To, From, Subject, Cc, Date” (in 10.1% of emails), the “=20” problem (in 6.4% of emails) due to mismatch in write
and read encoding, etc., This urges one to consider input formatting before processing this data for NER. Regular expressions 3 are used to find these noisy patterns and replace them with empty strings. This pre-processing is provided as a
Enron email fields excluding the body
The Enron email corpus introduced in consists of internal email messages that were made public by the Federal Energy Regulatory Commission (FERC) during the investigation of Enron scandal. The latest version released on May 17th 2015 2 consists of 517,431 emails from 151 users. Each email consists of several categorical fields like To, From, Cc, Bcc, etc., and also unstructured raw fields like Body and Subject. For our analysis we only consider the body of the email which consists of linguistic text information and ignore other fields, as they mostly contain meta-data (refer Fig. 4.1) which is non-linguistic
and adding them would lead to a noisy data which will disrupt the natural language information that is present in the body. An analysis of the email messages reveals a lot of noisy data even in the email body which includes nested email threads such as “Forwarded By” (in 20.3% of emails), “Original Text” (in 14.2% of emails), residual embedded fields like “To, From, Subject, Cc, Date” (in 10.1% of emails), the “=20” problem (in 6.4% of emails) due to mismatch in write
and read encoding, etc., This urges one to consider input formatting before processing this data for NER. Regular expressions 3 are used to find these noisy patterns and replace them with empty strings. This pre-processing is provided as a . This extensively pre-processed enron email data is a contribution of this research.
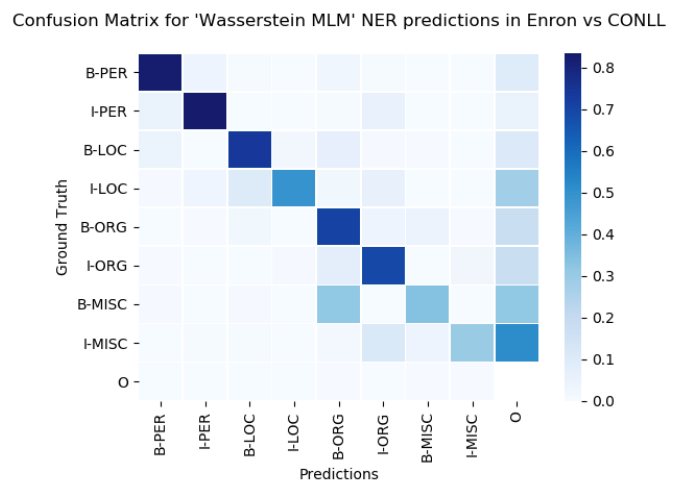 Confusion matrix with entities as axes normalized over Ground Truth for Enron vs CONLL in the best performing (best separation) model
Confusion matrix with entities as axes normalized over Ground Truth for Enron vs CONLL in the best performing (best separation) model
Complete results are not presented due to the confidential nature of the internship